
比赛于 2024/11/11 18:00 结束,我们队伍以 510 满分,全国排名第 19,北京赛区第 2,校第 1 的成绩通过初赛,在此感谢我的队友(@Soulter、@z2z63),大家都太棒了!
一些资料
- 比赛链接:https://open.oceanbase.com/train?questionId=600010
- 榜单:https://open.oceanbase.com/competition/armory
- 我们的代码仓库:https://github.com/bosswnx/miniob-2024
队友的记录(写得比我硬核多了!墙裂推荐去看看~):
一些工具:
- SQL 语法:https://www.runoob.com/sql/sql-syntax.html
- 在线运行 MySQL:https://onecompiler.com/mysql/42vjtvyn7
建议开发顺序
首先建议先写 update 和 date。前者可以让你熟悉 miniob 的整体框架,以及 sql 的执行流程;后者可以让你熟悉如何添加一个新的类型。
接下来建议直接写 expression,并且把能够用 expression 替换的东西尽早全部替换,比如 yacc 里的 attr。一是因为 expression 的思想很优美,实现了之后可以大大减化代码的复杂度和耦合度,二是防止后期需要改 expression 的时候才发现需要重构大量的之前写的代码,那时候就已经晚了。
接下来就可以选择性地去写想写的功能了,有很多的功能都是独立的,相互之间不影响,因此可以将类似的功能全部交给一个人写,比如 multi-index 和 unique 都是和索引有关,vector 相关功能等等 。
需要额外注意的是,一些题目的测试会依赖之前其他题目实现功能,这些题目建议放在更后面写。比如 null 的测试里就依赖了 unique,所以在实现 unique 之前是没法测试 null 的。
题目解析
这里只记录我自己参与的题目的写法,不一定是最优解,且可能会有些许错误,仅供参考。其他题目的写法可参考我的队友博客或其他文章。
Update
更新数据,没什么好说的,需要在更新实际表里的数据的时候,注意不要直接进行更改,而是应该把数据复制到一个临时变量进行更新,更新成功之后再覆盖回去,防止更新失败但是表里的原数据依然被更改。
除了更新表内的数据,还需要注意更新索引。做法是:更新数据的同时,将旧的索引项删去,插入新的索引项就好了。这里需要注意的一点是,如果更新失败了,还需要将之前删去的索引项重新加回来,才能正确维护索引。
Date
date 类型的格式是 YYYY-MM-DD,可以用一个格式为 YYYYMMDD 的 int 类型存下来。输出的时候在年月日中间插入 - 然后转换成 string 输出。
输入的时候需要检查日期的合法性,输出的时候如果日期是个位数,需要前补 0。
在语法分析阶段创建 Value 的时候就判断日期的合法性,如果不合法,调用 unset() 方法使其成为 UNDEFINED类型未初始化的值,然后在后续的 createStmt 中检查到的时候返回 FAILURE。
关于新建一个新的类型,需要在以下地方添加内容:
common/type/data_type.cppcommon/type目录下新建date_type.{cpp,h}common/type/attr_type.h里的class AttrTypecommon/type/attr_type.cpp里的ATTR_TYPE_NAME[]common/{value.cpp,value.h}里补充与 date 有关的内容sql/parser/{lex_sql.l,yacc_sql.y}中补充 date 类型的语法解析
一些需要注意的点:
- 在读入 date 的时候,需要判断日期是否合法(例如闰年、大小月等),如果不合法需要返回 FAILURE。
- 读入 date 的时候,如果日和月是个位数,其前面的前导 0 是可以省略,依然是合法的。
Null
和 date 类似,就是新增一个数据类型。
但是在实际的表中,我们无法用任何值来代表当前值是 null,因为任何值都是有实际意义的。所以为了表达一个值是 null,需要在每一个 record 开头新增一个 bitmap,其长度就是这个 record 的字段数量。每次解析 record 的时候,需要将前面的 bitmap 先解析出来,然后才是每个字段实际的值。
一些需要注意的点:
- 我们把 null 当成是一个新的数据类型来处理,而不是某一个数据类型值为 null,这样可以处理在 select 语句中识别到 null 后无法确定其数据类型的问题。
- null 做任何算数运算得到的返回值都是 null。
- 在聚合函数中会直接忽略 null,例如:null 不会使 count 聚合函数 +1。
- 如果聚合函数聚合的所有值都是 null,那么除了 count 会返回 0 以外,其他聚合函数都会返回 null。
- 在排序中,null 会被当成无穷小处理,所以我们需要为排序的情况新设计一个 compare 函数,将 null 排序到最前面。
Expression
expression 是一个很有意思的东西。其是一个抽象程度非常高的概念:字段可以是 expr,算数运算可以是 expr,聚合函数可以是 expr,甚至子查询也可以是一个 expr。而且 expr 可以有子 expr,相当于是这个 expr 的值依赖于子 expr。
通过 expr 的 get_value 函数,我们只要提供给他一个实际的 tuple,就能够通过递归的方式获得这个 expr 的值。这是一个很优美的方法,这样我们只需要实现每一类 expr 自己的 get_value 函数,就可以直接得到一个很复杂的 expr 的值。有一句话叫做「任何东西都可以看作是一个 expression」,很好地诠释了这一优点。
阅读 expr 相关的代码会发现,今年的框架已经为 expr 实现了很多具体的类了,例如前面提到的字段:
UnboundFieldExpr:还没有和 table 绑定的字段;FieldExpr:已经和正确的 table 绑定了的字段。
去年的这个时候,由于我们很晚才做 expression,导致原本很简单能够实现的功能,我们用了很复杂的方案来实现,比如聚合函数。这导致再后续的题目处理起来难度非常高。所以我们花了好几天的时间来把代码进行重构,最终导致时间不够,遗憾止步初赛。所以今年我们优先实现 expression 的相关功能,并且尽可能地把所有能替换成 expr 的部分全部都替换了。
这里举一个具体的例子吧。
在原本的 where 语句中,使用的是 attr comp value 的方式来语法匹配和处理,所以只能支持单个 attr 和单个 value 的比较。在后续生成执行计划的阶段,才会将列和值转换成 expression。
但其实可以直接在 expression 的语法解析里加上 UnboundFieldExpr,将比较运算符通过 ComparisonExpr处理,这样直接就在语法解析的时候直接识别一个 expr,这样任何的 expr 就都可以支持 where 语句了。
聚合函数
今年的聚合函数和去年差别蛮大的。去年框架里完全没有聚合函数的任何实现,今年的框架已经提供了很多和聚合函数相关的内容了,只需要在框架的基础上继续补充完整就好了。
聚合函数总共有 5 个:count、max、min、avg、sum。
今年的框架新增了 aggregator.h 文件,直接在里面依照模板来增加新的聚合函数就可以了。所有的聚合函数类都有两个共有的方法:accumulate()和 evaluate(),前者的作用是传入一个 Value,将其聚合到当前这个聚合函数里;后者的作用就是输出聚合函数的结果。所以只需要补充这几个缺失的方法就可以了。
一些需要注意的地方:
- 聚合函数表达式刚刚被解析出来的时候应当是
UnboundAggregateExpr类型的。在绑定的过程中,就可以检查聚合函数的一些合法性。 - 聚合函数不能和非聚合函数同时出现,并且聚合函数不能嵌套。
- select 子句中的非聚合列必须完全匹配 group by 子句中的列。否则就是语法错误。对应的检查应当在 create stmt 过程中。
Group By
group by 是和聚合函数一起使用的,相当于对聚合函数进行分组,能够统计出不同的聚合函数。group by 的处理是在 create_group_by_plan() 函数中处理的。
源代码中与 group by 相关的物理算子有两个:HashGroupByPhysicalOperator和 ScalarGroupByPhysicalOperator。前者是普通的 group by 算子,后者是没有 group by 表达式的物理算子(也就是直接执行聚合函数)。
一些需要注意的地方:
- 出现在 select 中的非聚合列必须也出现在 group by 中;相反,出现在 group by 中的列可以不出现在 select 中。group by 会把 null 分类在一起,需要在分类判断的时候单独处理 null(因为 null 和任何东西比较都返回 null)。
Order By
就是排序。新建一个算子,位于 ProjectPhysicalOperator的后面。open() 的时候将子算子全部执行完,得到的结果存下来排序,然后 next() 的时候再挨个输出就好了。
order by 物理算子内部使用一个 vector<unique_ptr<ValueListTuple>> 来缓存查询上来的数据,然后调用 std::sort,重载一个比较函数就可以对指针进行排序了。这种方式只会交换指针,而不会交换值,效率更高。
一些需要注意的地方:
- 在语法解析 order by 表达式的时候,需要注意表达式的顺序,因为 order by 是有先后顺序的。
- null 在 order by 排序中被当成是无穷小处理。
Multi-index
multi-index 要完成的是将 index 修改为支持在多个字段上建立,原本 miniob 的 index 采用是 B+tree,只支持在一个字段上建立。
b+tree 是以 key-value 的形式存储数据的。value 只存在于叶子节点上,key 则可以同时存在于叶子节点和中间节点。原本的 miniob 中,key 是由一个 attr 和 rid 拼接而成,rid 是为了防止 attr 重复。
为了支持多字段,我们需要将原本的单个 attr 拓展成支持多个 attr 的形式,其实就是多个 attr 拼接在一起,最后再把 rid 拼上。多个 attr 参数的传入可以直接用 vector 来实现。
需要注意的是:对于 struct IndexFileHeader,由于其需要存储在一个页面中,最终在硬盘中永久化,所以不能在里面使用 vector 等 STL,因为 vector 其实只是一个指针,其数组内容实际上不在这个结构体内,所以只能采用普通的数组。因此,我们还需要确定数组的长度,而这个长度可以通过计算页面的大小减去其他结构体内的变量的大小来确定:
const int MAX_KEY_NUM =
(BP_PAGE_DATA_SIZE - sizeof(PageNum) - 5 * sizeof(int32_t)) /
(sizeof(AttrType) + sizeof(int32_t));
struct IndexFileHeader {
PageNum root_page; ///< 根节点在磁盘中的页号
int32_t internal_max_size; ///< 内部节点最大的键值对数
int32_t leaf_max_size; ///< 叶子节点最大的键值对数
int32_t key_length; ///< attr length + sizeof(RID)
AttrType attr_types[MAX_KEY_NUM];
int32_t attr_lengths[MAX_KEY_NUM];
};
Unique
这题的目标是实现支持唯一 key 的索引。如果对一个表建立的 unique index,再往里插入的时候,需要判断索引的 key 是否重复,如果的话就不能插入。更新也是同理。
这题比较难的地方是需要实现对 null 的支持。unique index 允许多个 null 值。也就是说,如果某一列被定义为 unique,你可以在该列中插入多个 null 值。
我们的做法传入了一个新的参数 is_unique 代表这个 index 是不是 unique 的。如果是的话,就在 insert 的时候只比较 user key 部分而不比较 rid 部分。至于为什么只在 insert 的时候有区别,是因为在 delete 的时候,依然需要 rid 部分来确定是这个 record,否则只要 user key 部分相同,就都能删除,这肯定是不对的。
除此之外,还需要支持 null。null 在 unique index 中依然可以重复存在。
框架原本的 index 采用的 B+ 树的 key 值比较简单,就是单纯地传入值的数据 const char * user_key, 然后利用 index_meta_ 里存的 field_metas_ 来进行判断数据的类型,进行大小判断。但是单纯的 user key 是没法表达 null 的。所以为了实现对 null 的支持,我们需要将其改成传入更为具体的 Value 类型,还需要在 B+ 树的节点中加入一个 bitmap,来判断某一个字段是否是 null。
但是由于正确的做法需要在原来框架的基础上改动太多的代码,我们并没有采用,而是用了另一种:在 B+tree 的每个字段前多留 4 个字节的空间(使用 4 个字节而不是 1 个字节是因为需要保证内存对齐),用来表示当前字段是否是 null。这样虽然比 bitmap 浪费了更多空间,但是不需要改动太多的代码,对于比赛来说更有利。
Update MVCC
本来这题应该是不会有问题的,只要实现了前置的功能这个可以直接过,但是我们队伍不知道为什么过不去。研究了一下发现,错误应该是和 field_id 的维护有关。
在 mvcc 模式下,miniob 会创建一些隐藏字段在我们声明字段前,来实现 mvcc 的相关功能。隐藏字段的数量可以通过 TableMeta::sys_field_num() 来得到。所以我们自己声明的字段是位于 sys_field_num() 到 field_num() 之间的。但是我们在一些进行字段比较的地方,错误地将下标从 0 开始匹配,导致读取了错误的字段,从而产生了一系列问题。将 field id 正确维护之后,这题就过了。
一些其他问题
erase 迭代器不规范删除
今年我们开了许多代码质量检查,导致框架代码暴露出了许多 bug(miniob 的代码质量真的令人堪忧啊)。其中有一个是检查代码是否有未定义行为,开启这个检查后框架代码连 basic 都过不去了。debug 完之后发现,是框架里使用迭代器 iter 的时候,直接 erase 了 iter,而没有更新导致的。
框架里是这么写的:
for (auto iter : ...) {
some.erase(iter);
}
正确的写法应当是:
for (auto iter : ...) {
iter = some.erase(iter);
}
erase()是有返回值的,其返回值是 iter 在 erase 之后应当位于的迭代器位置。我们在比赛过程中遇到了很多地方都有这个 bug,需要注意改一改。
一些其他队友写的时候遇到的问题
- text 要注意将 observer 和 obclinet 的收发缓冲区增大,不然可能会过不去评测。我们从 8K 增大到了 8M 才通过的评测。
- having 中的表达式必须使用 group by 中包含的列,或者聚合函数,不能使用其他列。
一些小插曲
由于我们的 vector 相关的题目都是一个队友负责的,他在最后一周沉淀了四天之后一发把所有的 vector 相关题目一起过了,而我们也因此得到了……
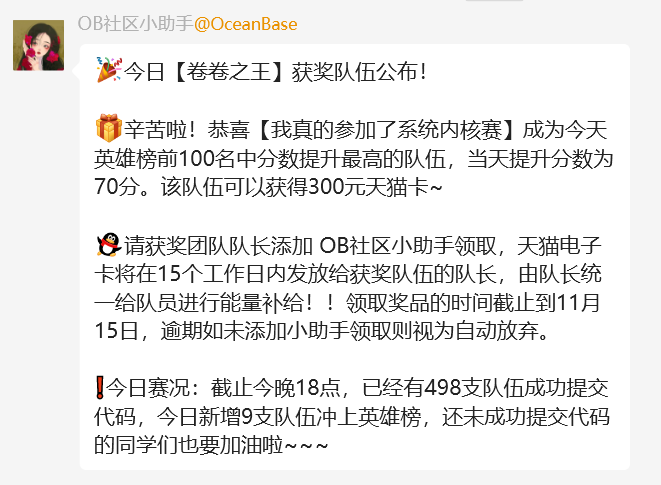
以及比赛的时候发现今年北京赛区相比去年变得一点都不卷了(无恶意):
最后的最后
去年以一题之差倒在了初赛最后一刻,今年终于实现了去年未能完成的夙愿,成功以满分的分数完成了初赛!感谢我的队友们,这段时间大家的日均代码都超过了 5h,三个人一起凌晨四点还奋战在代码一线的场景我依然历历在目!最后感谢学校发的 8k 哈哈哈,去年没得到的今年我一定要拿回来(x